
A Q&A with Pete Diffley
As demonstrated by collaborative tools like Git and GitHub, the broader software development world has come a long way when it comes to version control. State-of-the-art version controls allow users to revert selected files to a previous state, compare changes over time, see who last modified something that might be causing a problem, who introduced an issue and when, and more. In short, if you screw something up—you can gracefully recover. But much of today’s industrial software, such as applications used for programmable logic controller (PLC) configuration or human-machine interface/supervisory control and data acquisition (HMI/SCADA), includes no inherent version control. They rely instead on fallible and often hurried human developers to follow manual version control work processes for which spotty follow-throughs are of little consequence. That is, until they are.
As a longtime end-user and integrator, Pete Diffley has more than once been called on to troubleshoot a malfunctioning production line where modified programming brought output to a halt—only to find himself immersed in inscrutable code with no traceable return to the latest working version, even as the cost of downtime mounted at an alarming pace. He doesn’t recommend the experience.
Rather, as senior manager of global partnerships for Trihedral Engineering, he’s now an advocate for application software that includes inherent version control capabilities because they facilitate both development efficiency and operational resilience. Control caught up with Diffley to discuss the history of version control approaches and why an inherent capability for version control is the best approach for more reasons than one.
Q: Short of an inherent and automatic functionality built into an application software package, what were some of the more basic solutions to the version control problem?
A: At its most fundamental, the intent of version control is to facilitate retracing one’s steps to an earlier state—whether to undo an error or revert to a past version that was known to operate correctly. Perhaps the simplest and most immediate incarnation of version control is the pervasive “undo” button, which typically only allows the developer to retrace 10 or perhaps 15 of their latest actions—and then only if he/she hasn’t saved their work in the interim.
Saving one’s work periodically with a date/time-stamped file extension is another way version control can be accomplished—but it requires that the programmer periodically interrupt the flow of their development work, which takes time and saps productivity.
With Windows XP, Microsoft platform users were first given the ability to capture a “restore point,” effectively a snapshot image of the entire Windows machine. These could be set to happen automatically at prescribed intervals or kicked off manually to provide, in theory at least, a point you could go back to should your operating system crash.
A common limitation of these archival approaches is that they’re purely sequential; you can go back in time to a previous version, but it’s all or nothing. You can’t pick and choose which changes to undo. If you developed your best work since the restore point, you would lose this anyway. Also, they rely on the discipline of the developer to remember to save their work—or at least resist the temptation to override the automated creation of a restore point in the course of it.
Q: Wouldn’t the management of saved software versions and time-stamped restore points introduce yet another file management headache, especially when there are multiple developers involved?
A: That’s right. Everyone would need to be saving those versions to the same folder somewhere in the corporate network, and those versions should also be annotated as to what changes are reflected in it and for what purpose since the last saved version. It’s huge overhead and a documentation chore that’s easily overlooked or neglected. In the past, I’ve witnessed how this process was derailed on large infrastructure projects, with developers putting out frantic calls to their colleagues asking, “Does anyone happen to have the latest copy stored locally?”
Q: Aren’t there now independent, third-party version control packages that can be used to create a version control archive of my HMI/SCADA code?
A: Yes, that’s true. It helps somewhat, but integrating a third-party version control package with application software to be tracked also introduces a significant level of complexity and overhead. Typically, each time something is done in the HMI/SCADA package, code and commentary about the changes needs to be added to the tracking software. It is a manual burden that can eventually lead to the developer skipping a step to save time. When something goes wrong it may or may not be possible to revert to a prior change. In general, the more integrated the better.
Q: How does inherent version control work, and what makes it a better solution?
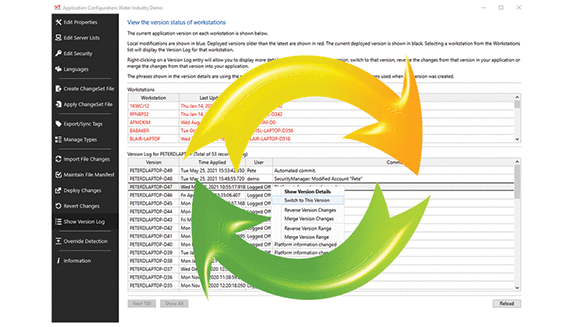
A: Inherent version control means the application software itself carries within it a record of every change that’s ever been made. Each programming change is an internally tagged event; the application software captures the nature of the change, when it was made, and who made it. Each of these events can be examined independently and reversed or corrected as necessary. And that reversal or correction becomes yet another event that’s captured by the system, so it too can be changed.
In the case of Trihedral’s VTScada software, our mindset has always been to make the complex easy to implement. For example, our Advanced Version Control is built into the software. It’s not some kind of bolt-on application. It works away silently in the background, automatically capturing every change you make to the software. If you create a masterpiece in integration terms, and later realize you made a mistake somewhere in the middle, rest assured that you can go back and change whatever needs to be done. If you’re working with a team of developers on the same project, it’s extremely easy to keep track of who has done what, when and where. If a team member needs to make a change to something embedded in a co-contributor’s work, you can reverse, change or merge it singularly if needed, with just a few mouse clicks. This is logged as a change also. It’s immensely powerful. Developers have often called to say it’s their “guardian angel” and it’s one of the most powerful features of our software.
Q: And this also leads to better operational resilience, right?
A: Absolutely. A change applied to a system by an integrator may have a consequence that remains undetected on the production system for some time. Trying to identify the change that was made that caused the issue can be a nightmare, especially if the person who made the change is no longer available. Version control becomes the hero that steps in to save the day.
This philosophy of making the complex easy to implement is what makes our software so powerful. The software’s event-driven architecture allows users to easily scale up from very small to extremely large, highly resilient mission-critical systems.
The bottom line is a clear path to operational resilience—all without hampering development efficiency.