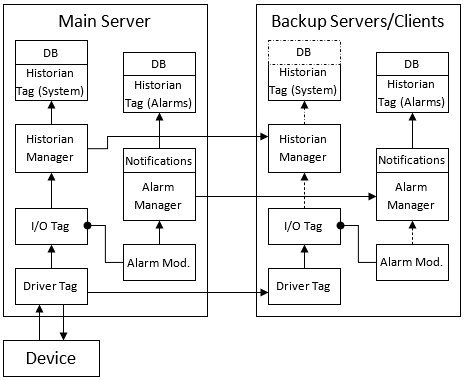
Simplified VTScada Communications Architecture
VTScada is made up of many independent modules that run locally, but benefit from a well-tested Remote Procedure Call (RPC) service. One feature this provides is to manage inter-server communications (from one VTScada server to another) and guarantee that only a single machine becomes the server for a given process.
The RPC service also looks after synchronization between servers. As an example, consider modules that run as tags. The RPC service guarantees that their stored parameters are synchronized between servers. Variables that are not defined as parameters are synchronized only if the module they are within either registers its own RPC service or uses the service provided by another module, such as a driver.
In a typical data acquisition and presentation scenario, an I/O tag will ask a driver to provide the value associated to its address. The driver will request that value through its own method, which is usually a protocol exchange with an external device, such as a PLC. The request operation takes place only in the server currently assigned to the driver’s RPC service. When finished, the driver calls the standard VTSDriver service, which updates the local tag through direct assignment and sends an RPC update message to the same instance of the service on all other connected servers. Those update their local versions of the requesting tag modules, thus assuring that the same tag reports the same value on all servers.
If the I/O tag is configured to enable logging to an attached Historian tag, then that I/O will ask the Historian to log its value. Because all instances of the tag, running on different servers, receive the same data, and have no knowledge of the source of such data (direct communication or RPC broadcast), all will request the Historian to store the value and timestamp. But, because the Historian has an RPC service of its own, it will only perform “data authoring” (attaching the proper timestamp) if it is running on the current Historian server. In that case, it will write the data to the assigned database engine (either the internal file DB or an external ODBC-connected server). Afterward, it will send an RPC broadcast message to all other Historian servers, which will store a copy of that data, rather than the version sent by the local I/O tag. This guarantees that it will be assigned the same timestamp on all servers, thus avoiding duplicate records.
A parallel task, either run inside the I/O tag or through a connected alarm tag, will evaluate the value locally on all machines, through a call to the Alarm Manager, which also runs an RPC service. The alarm status returned by the tag itself will be defined locally, while the alarm event will be raised by the Alarm Manager, but only if running on the current alarm server. Like the Historian (which uses the same engine), it will record an alarm event to the database and broadcast it to all other servers. The main difference is that Alarm Historian tags are usually configured to enable Client Storage. It means that all clients are going to act like passive servers, regardless of whether they are included in the server list. In other words, they will always receive new alarm records from the server, and will try to log those events themselves if unable to communicate with the server. The alarm notification system is based on the alarm records, which will synchronize their notification behavior based on the status currently defined on the database and therefore synchronized across the network.
A simplified diagram of the process follows. This assumes a simple server list with the same machine holding the server role for all communications, historian and alarms. A dashed arrow means that the request will be usually ignored, while dash-dot means it will be ignored on pure clients: